From time to time our backups were failing on the ORA-00245 error
|
0 Comments
ORA-39083 - Object type TYPE failed to create. ORA-02304: invalid object identifier literal8/18/2015 During the import using impdp, several errors occured:ORA-39083: Object type TYPE failed to create with error:
ORA-02304: invalid object identifier literalFailing sql is:CREATE TYPE "ECMST2"."TX_ECMS_EXCEPTION" OID 'EAF92B3811A604E4E0430A3C040104E4' as object ( error_code varchar2(30), --Error business code result_code number, --Result code returned by API - 8 - error, 4 - warning, 255 - unhandled exception error_desc varchar2(4000), --Error description placeholders_desc varchar2(4000), --Description of placeholders used in error_desc sql_code number, The problem is, that import is trying to craete a new object with the same OID. to solve the problem, the TRANSFORM=OID:n has to be added to the impdp command: impdp directory=IMPORT dumpfile=ecms_test2.dmp logfile=ecms_t2_imp.log schemas=ECMS remap_schema=ECMS:ECMST2 remap_tablespace=USERS:ECMS_T2 transform=OID:n After we have killed the user who has ran a delete command for more than 5 hours, the parallel recovery has started with 47 processes active. The whole production server was under heavy load an massive delays occured on all our PROD databases.
I was trying to reach the Enterprise Manager Grid Control 10g using the https on port 4889.
Today we have faced strange problem. The customer was complainig, that his java stuff in the database is not working. The rror he has received was: 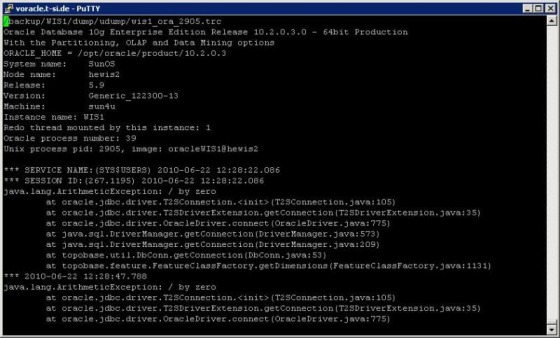 After some investigation, I found, that the database has crashed in the morning. The crash was caused by some ORA-600 error: 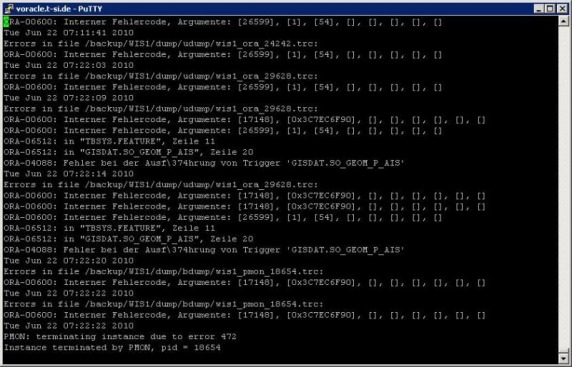 Few minutes after the crash one of my colleagues hast started the database. Then some new ORA-07745 occurred:   At this moment customer started to complain, that his java based procedures are failing with the division by zero error. I started to look on Metalink. In the ORA-600 and ORA-07745 Tool I have found one SR, in which someone else was facing same problem. One of the reasons could be, that the database was started with wrong LD_LIBRARY_PATH parameter. As this was for a solaris machine, the pldd command should be used to see, which libraries the process is using. So I run the command over the smon process: 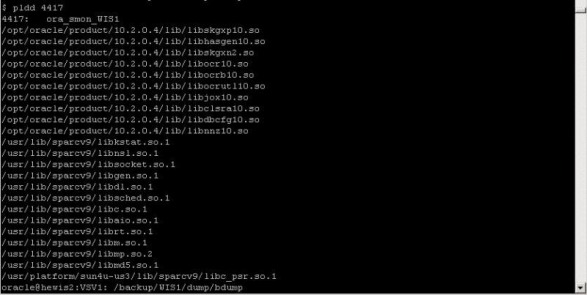 And there was the problem. The 10.2.0.3 database was using 10.2.0.4 libraries. Therefore the division by zero and ORA-07745 errors. After this we have stopped the database, set correct LD_LIBRARY_PATH parameter and started the database. The ORA-07745 and java error were gone. But unfortunatelly another java error occured: 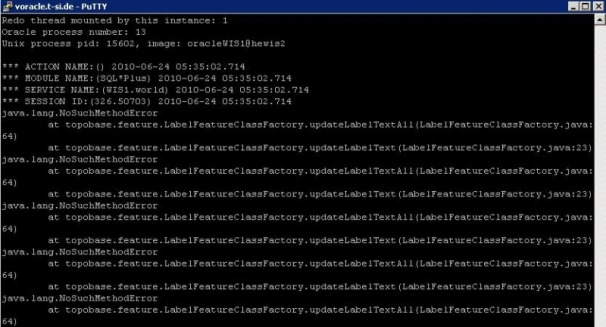 We have tried recompile whole java schema and also some other schemas in the database, but without success. We also opened a SR on metalink. On the other day, customer received some hints from the vendor of the application. They should run some udateStructure script. So we have restarted the database and customer run his script. After this, the problem was resolved. The only problem we should look after was, why there was wrong LD_LIBRARY_PATH, when we wer using oraenv script to change the variables. After few minutes it was clear, that the oraenv script is not setting correct LD_LIBRARY_PATH parameter. After logging on the server, the environment for the 10.2.0.4 was set as default. When you run oraenv script, the oraenv from 10.2.0.4 was started. And in this script there was no LD_LIBRAY_PATH parameter, so the default for 10.2.0.4 was kept. So that's why the database was started with wrong parameter. We have modified the script and now it is working without problems.
Today, we faced a problem, that somebody accidentaly deleted symbolic links, which were pointing to the directory, where datafiles were located. It was a SAP database. There was a sapdata1 directory, where were all datafiles. And the there were sapdata2, sapdata3, sapdata4 directories, which were pointing to sapdata1. the unix guy accidentaly deleted those links. so the database was complaining, that the datafiles are not on the disks. As first thing we tryed was to create the symbolic links again. After the links were there, everything was back to normal. I wanted to understand this behaivior, so I tested it on my linux machine. The result was the same. SO I started to look on the internet, to find out, why it is so. And I found very interesting article from Franck Pachot. I have reproduced the whole scenario on my testing database, and here it is: First, I have created new tablespace in my database: create tablespace testing datafile '/oradata/ora10g/testing01.dbf' size 100M;  Now, we create table in it and fill it with data: create table testing tablespace testing as select * from dba_objects; 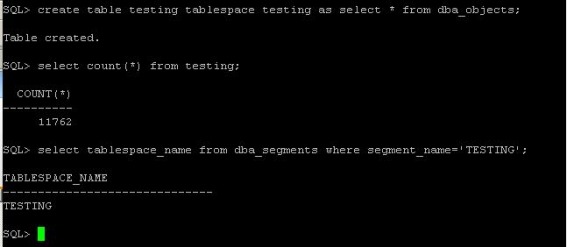 Now, I "accidentally" delete the datafile: 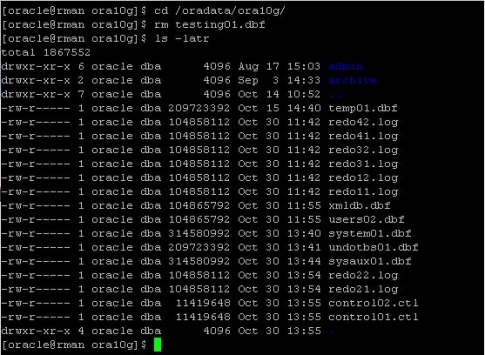 Now, when I want to insert data in the table I got an error: 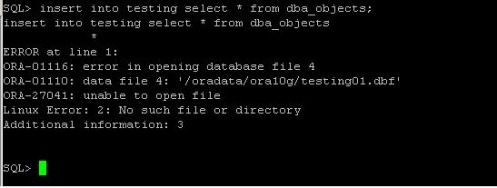 The datafile is not there and the data are not accessible. However, the datafile should have open file descriptor by an oracle background process. check the PID of the database writter:  In my case, it is 3427. And now, we check its opened file descriptors for our file: ls -l /proc/3427/fd |grep testing  The fd number is in my case 25 Now, first we set up an symbolic link, so the oracle will see the datafile as before deletion: ln -s /proc/3427/fd/25/oradata/ora10g/testing01.dbf  Now, the data are accessible again. But will be lost, if the DBW close its file descriptor (the DB restart). So now, we set the tablespace read only, so it will be checkpointed and no writes occurs on it.  Now, we can safely copy the file back to its directory. First we delete the symbolic link we created and then we copy the datafile:  Now, we have the data back, so we can put the tablespace back to read write mode and try to insert in the table: 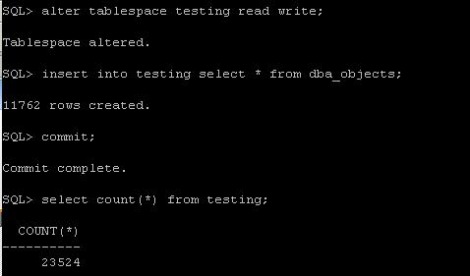 This is not to be used like that in production. This is unsupported and may behave differently on different unix/linux or oracle versions.
Today we have faced a strange problem. After the online reorganization of the PSAPBW3 tablespace was finished, i found out, that there are still 3 objects in the original tablespace. I searched through dba_segments view and found out, that both,the original table and the interim table, from the dbms_redefiniton exists. I tried to finish the reorganization wit dbms_redefinition.finish_redef_table, but got error ORA-12093: invalid interim table "SAPBW3"."/BI0/SSALES_OFF#$". I tryed to abort it trough dbms_redefiniton.abort_redef_table. The procedure finished successfully, but both tables were still in the database. We decided to drop the interim table and reorganize it again. I tried to drop the table, but got:
SQL> drop table "/BI0/SSALES_OFF#$"; drop table "/BI0/SSALES_OFF#$" * ERROR at line 1: ORA-12083: must use DROP MATERIALIZED VIEW to drop "SAPBW3"."/BI0/SSALES_OFF#$" Ok. so next thing, what I tryed was drop materialized view: SQL> drop materialized view "SAPBW3"."/BI0/SSALES_OFF#$"; drop materialized view "SAPBW3"."/BI0/SSALES_OFF#$" * ERROR at line 1: ORA-12003: materialized view "SAPBW3"."/BI0/SSALES_OFF#$" does not exist I have looked in the dba_mviews and the materialized view was not there. I have looked on the google, and metalink and I found out the 265455.1 It was not my case, but on the bottom, there was Note 148379.1 about Drop Table Fails with Error ORA-12083. I followed the note and created snapshot on the "SAPBW3"."/BI0/SSALES_OFF#$" table: SQL> create snapshot sapbw3."/BI0/SSALES_OFF#$" on prebuilt table as select * from sapbw3."/BI0/SSALES_OFF"; Materialized view created. After that I tryed to drop the table again: SQL> drop table sapbw3."/BI0/SSALES_OFF#$"; drop table sapbw3."/BI0/SSALES_OFF#$" * ERROR at line 1: ORA-12083: must use DROP MATERIALIZED VIEW to drop "SAPBW3"."/BI0/SSALES_OFF#$" It was not working, so I tryed to drop the materialized view: SQL> drop materialized view sapbw3."/BI0/SSALES_OFF#$"; Materialized view dropped. After that I was able to drop the stupid table: SQL> drop table sapbw3."/BI0/SSALES_OFF#$"; Table dropped. And voila... The table was gone: SQL> select segment_name,segment_type from dba_segments where segment_name like '/BI0/SSALES_OFF%'; SEGMENT_NAME SEGMENT_TYPE --------------------------------------------------------------------------------- ------------------ /BI0/SSALES_OFF TABLE /BI0/SSALES_OFF~0 INDEX /BI0/SSALES_OFF~00 INDEX After this, we ran the online reorg of the table again, and the old tablespace was empty :-) Because right now I am working as a DBA in the SAP team, I needed to know, how online reorganization of tables works. The guys from SAP team have it easy. they just run brtools with some parameters and the program take care of whole online tablespace reorganization. As I have checked the progress of the reorg, I found out that table which was reorganized had bigger size as the original table. I didnt knew, what was the cause so I started the investigation. I tried to trace the session, to find out, what it was doing. I was looking thrugh the trace file, but didnt find the cause. Next day morning I was just trying to reproduce this behavior and I found out, that the real cause is the primary key. :) Yes.. It is so simple. When you reorganize the table with the primary key, everything is fine. Even the size of the new table. But when you dont have a primary key, you need to reorganize the table using the ROWID. And to do this, oracle adds a hidden column M_ROW$$ to the table. After all the steps of rdbms_redefinition are completed, the hidden column is set as UNUSED. And that was the problem, why I saw, that the reorganized table had more extents than the origin table. :)
Here is my test case: I have created a table called test with 2 columns a int and b varchar2. I have filled this table with 8 milion rows. There is unique index TEST_IDX on the "a" column. I will move the table from the TEST tablespace to the USERS tablespace. 1, Reorganization using the ROWID SQL> select segment_name,segment_type,bytes/1024/1024 "MB",tablespace_name from user_segments; SEGMENT_NAME SEGMENT_TYPE MB TABLESPACE_NAME ------------------------------ ------------------ ---------- ------------------------------ TEST TABLE 192 TEST TEST_IDX INDEX 144 TEST -- first you need to create the new table: SQL> create table test_tmp as select * from test where 1=2; Table created. SQL> select segment_name,segment_type,bytes/1024/1024 "MB",tablespace_name from user_segments; SEGMENT_NAME SEGMENT_TYPE MB TABLESPACE_NAME ------------------------------ ------------------ ---------- ------------------------------ TEST_TMP TABLE .0625 USERS TEST TABLE 192 TEST TEST_IDX INDEX 144 TEST -- now you will test, if the table isa candidate for online reorganization: SQL> exec DBMS_REDEFINITION.CAN_REDEF_TABLE('TEST','TEST',2); PL/SQL procedure successfully completed. -- now you run the online reorg. SQL> exec DBMS_REDEFINITION.START_REDEF_TABLE('TEST','TEST','TEST_TMP',options_flag=>dbms_redefinition.cons_use_rowid); PL/SQL procedure successfully completed. --copy the table dependents SQL > declare error_count pls_integer := 0; BEGIN dbms_redefinition.copy_table_dependents('TEST', 'TEST', 'TEST_TMP',1, true,true,true,false,error_count); dbms_output.put_line('errors := ' || to_char(error_count)); END; / PL/SQL procedure successfully completed. -- synchronize the tables SQL> exec DBMS_REDEFINITION.SYNC_INTERIM_TABLE('TEST', 'TEST', 'TEST_TMP'); PL/SQL procedure successfully completed. --finish the reorg SQL> exec DBMS_REDEFINITION.FINISH_REDEF_TABLE('TEST', 'TEST', 'TEST_TMP'); PL/SQL procedure successfully completed. Now you can see, that the new table, is bigger, than the original one: SQL> select segment_name,segment_type,bytes/1024/1024 "MB",tablespace_name from user_segments; SEGMENT_NAME SEGMENT_TYPE MB TABLESPACE_NAME ------------------------------ ------------------ ---------- ------------------------------ TEST TABLE 360 USERS TEST_TMP TABLE 192 TEST TMP$$_TEST_IDX0 INDEX 144 TEST TEST_IDX INDEX 144 TEST In the user_unused_tab_cols view you can see, that both tables have unused columns: SQL> select * from user_unused_col_tabs; TABLE_NAME COUNT ------------------------------ ---------- TEST 1 TEST_TMP 1 And that is the reason, that new table has bigger size :) 2, reorganization using PRIMARY KEY The scenario with the table is the same. The only difference is, that I will create constraint (primary key) on the "a" column. -add primary key SQL> alter table test add constraint pk_a primary key(a); Table altered. SQL> create table test_tmp as select * from test where 1=2; Table created. SQL> select segment_name,segment_type,bytes/1024/1024 "MB",tablespace_name from user_segments; SEGMENT_NAME SEGMENT_TYPE MB TABLESPACE_NAME ------------------------------ ------------------ ---------- ------------------------------ TEST_TMP TABLE .0625 USERS TEST TABLE 190.625 TEST TEST_IDX INDEX 144 TEST --now the reorg: SQL> exec DBMS_REDEFINITION.CAN_REDEF_TABLE('TEST','TEST'); PL/SQL procedure successfully completed. SQL> exec DBMS_REDEFINITION.START_REDEF_TABLE('TEST','TEST','TEST_TMP'); PL/SQL procedure successfully completed. SQL> declare error_count pls_integer := 0; BEGIN dbms_redefinition.copy_table_dependents('TEST', 'TEST', 'TEST_TMP',1, true,true,true,false,error_count); dbms_output.put_line('errors := ' || to_char(error_count)); END; / PL/SQL procedure successfully completed. SQL> exec DBMS_REDEFINITION.SYNC_INTERIM_TABLE('TEST', 'TEST', 'TEST_TMP'); PL/SQL procedure successfully completed. SQL> exec DBMS_REDEFINITION.FINISH_REDEF_TABLE('TEST', 'TEST', 'TEST_TMP'); PL/SQL procedure successfully completed. --and the result: SQL> select segment_name,segment_type,bytes/1024/1024 "MB",tablespace_name from user_segments; SEGMENT_NAME SEGMENT_TYPE MB TABLESPACE_NAME ------------------------------ ------------------ ---------- ------------------------------ TEST TABLE 192 USERS TEST_TMP TABLE 190.625 TEST TMP$$_TEST_IDX0 INDEX 144 TEST TEST_IDX INDEX 144 TEST The new table is almost the same size as the original. Just 1.4 megabytes difference. On the oposite of the 168 Megabites in the first example. |
NiscoHere, in this section, I will write some usefull thing, I have learned during my everyday work. Archives
August 2015
Categories |
 RSS Feed
RSS Feed
